This post focuses on linked data and what new catalogers need to know. Catalogers working in technical services now are expected to adapt to changing and growing roles that require skills and knowledge outside of traditional OPAC cataloging duties. This can include metadata work, cataloging of unique digitally born items, and possibly even linked data initiatives.
I’m going to start out giving a very high-level explanation of linked data and the technological foundation for all linked data initiatives. Then I will move on and discuss linked data and libraries: why, how, and when. It is essential that all new catalogers have a good understanding of what linked data is, so they can recognize if and when their library needs to start their own local linked data initiatives.
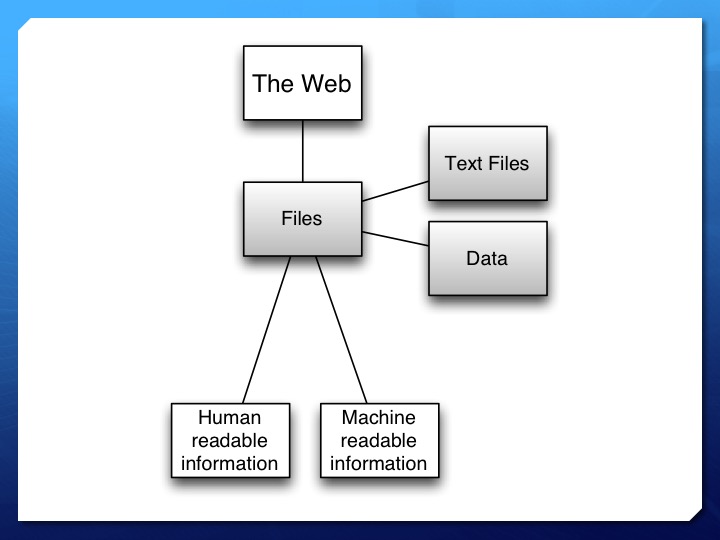 The web is made up of files of various formats. Some of those files are text-based documents, such as html, pdf, or xml. Text files are what most web users actually access when they surf the web for information. But text-based documents do not account for all of files on the web. The web also contains data files. Data files can be commonly used file formats such as comma separated value files and tabular data, or a unique format created specifically for that file of information. Common types of data files put up on the web include scientific data and government provided data, such as the United States Census.
The web is made up of files of various formats. Some of those files are text-based documents, such as html, pdf, or xml. Text files are what most web users actually access when they surf the web for information. But text-based documents do not account for all of files on the web. The web also contains data files. Data files can be commonly used file formats such as comma separated value files and tabular data, or a unique format created specifically for that file of information. Common types of data files put up on the web include scientific data and government provided data, such as the United States Census.
These files, both text and data, contain two general types of information: human readable information and machine-readable information. Human readable information is the stuff that matters to us. It is the information we opened that file to get: the actual intellectual content. Machine-readable information is the stuff that talks to your personal computer, the server it is hosted on, search engines like Google, and many other applications to tell those machines what do it with it.
 Here is an example of six different related files that might be on the web: a library record of a print government document, a dataset on a project website, a peer-reviewed article through Wiley Publishing, a government technical report in SciTech Connect, a preprint article in a university repository, and a dataset in a discipline based repository. Any one of us could look at the human readable information in the files and understand exactly how these six files are related to one another. In this case, they all have something to do with the same government funded scientific project. Computers, and most importantly search engines like Google that we rely on to find what we are looking for, only have the machine readable information supplied to make connections between files on the web.
Here is an example of six different related files that might be on the web: a library record of a print government document, a dataset on a project website, a peer-reviewed article through Wiley Publishing, a government technical report in SciTech Connect, a preprint article in a university repository, and a dataset in a discipline based repository. Any one of us could look at the human readable information in the files and understand exactly how these six files are related to one another. In this case, they all have something to do with the same government funded scientific project. Computers, and most importantly search engines like Google that we rely on to find what we are looking for, only have the machine readable information supplied to make connections between files on the web.
Overall, we do a good job making machine-readable information and search engine indexing possible for text documents. However, the same cannot be said for data. Because of this, most data available on the web remains siloed in its current location.
All linked data initiatives aim to improve machine-readable information so that computers can understand links between data files and enable better discovery and access to data as well as enable the creation of more interesting applications.
 Tim Berners-Lee, one of the main founders of the web as we know it today, has four rules for linking data on the web. The first: user URIs as names for things. URI stands for uniform resource identifier. It is important that not only the data files themselves have their own unique identifier, but also everything named in the metadata. For example, the title field must have a URI explaining to all machines that look at the data that this is the title. The second rule: use HTTP URIs so that people (and machines) can look up names. If the URI is in an http form it is easier for humans and machines to look it up and understand what it is. The third rule: when someone looks up a URI, provide useful information using the standards. Make sure you provide metadata information with URIs when possible. The last rule: include links to other URIs, so that related things can be discovered. As with RDA cataloging, there is an important emphasis on relationships. This helps people and machines make more connections and breaks down data silos.
Tim Berners-Lee, one of the main founders of the web as we know it today, has four rules for linking data on the web. The first: user URIs as names for things. URI stands for uniform resource identifier. It is important that not only the data files themselves have their own unique identifier, but also everything named in the metadata. For example, the title field must have a URI explaining to all machines that look at the data that this is the title. The second rule: use HTTP URIs so that people (and machines) can look up names. If the URI is in an http form it is easier for humans and machines to look it up and understand what it is. The third rule: when someone looks up a URI, provide useful information using the standards. Make sure you provide metadata information with URIs when possible. The last rule: include links to other URIs, so that related things can be discovered. As with RDA cataloging, there is an important emphasis on relationships. This helps people and machines make more connections and breaks down data silos.
 All linked data movements have the same technological foundation. First, they all use URIs and HTTP as discussed with Tim Berners-Lee’s rules. Next, most use RDF. RDF, or Resource Description Framework, is a metadata encoding standard. It encodes data in triples: subjects, predicates, and objects. Objects in an RDF record can become subjects for authority-like record work, which will become clearer on the next slide.
All linked data movements have the same technological foundation. First, they all use URIs and HTTP as discussed with Tim Berners-Lee’s rules. Next, most use RDF. RDF, or Resource Description Framework, is a metadata encoding standard. It encodes data in triples: subjects, predicates, and objects. Objects in an RDF record can become subjects for authority-like record work, which will become clearer on the next slide.
It is also essential that naming standards be developed. Data cannot be linked if everyone is using different URIs for the same objects and predicates. Two commonly used standards are RDF Vocabulary Definition Language and OWL, the Web Ontology Language. The need for controlled vocabulary skills in developing linked data initiatives is one reason many catalogers become directly involved when their institution begins linked data initiatives. Catalogers understand the importance of controlled vocabularies and have great experience in choosing and using them.
Another important part of the technological foundation is SPARQL. This is a database query language used to work with the RDF triples, which is stored as a database.
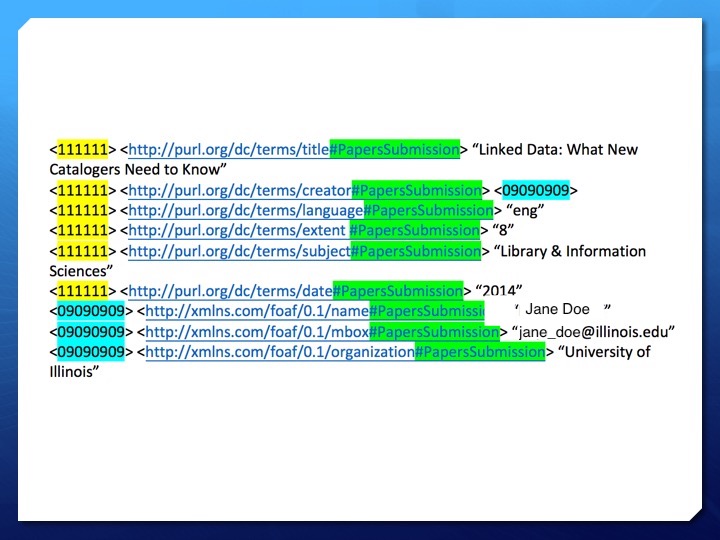 Here is an example of an RDF record in an example repository called Papers. Highlighted in the yellow on the slide is the subject of the set of RDF triples. It is the unique identifier for this repository record. In the middle is the predicate, which explains the relationship between the subject and the object. The predicates come from Dublin Core and FOAF vocabulary, but at the end of each predicate is a hash tag and another bit of information. This identified the data stream where the information came from, in this case PapersSubmission, an example submission application for the repository. Highlighted in blue is a person object. The creator predicate in the record identifies an “object” which has its own set of triples. The object in this record is myself. The triples give more information about me, such as my full name, email, and organization.
Here is an example of an RDF record in an example repository called Papers. Highlighted in the yellow on the slide is the subject of the set of RDF triples. It is the unique identifier for this repository record. In the middle is the predicate, which explains the relationship between the subject and the object. The predicates come from Dublin Core and FOAF vocabulary, but at the end of each predicate is a hash tag and another bit of information. This identified the data stream where the information came from, in this case PapersSubmission, an example submission application for the repository. Highlighted in blue is a person object. The creator predicate in the record identifies an “object” which has its own set of triples. The object in this record is myself. The triples give more information about me, such as my full name, email, and organization.
 So how are these new linked data records being used? There are three main types of linked data applications in use and being developed. The first are linked data browsers. Just like a web browser, such as Firefox or Chrome, that navigates html pages by hypertext links, data browsers navigate linked data by RDF triples. Two examples of this are Tabulator and Marbles.
So how are these new linked data records being used? There are three main types of linked data applications in use and being developed. The first are linked data browsers. Just like a web browser, such as Firefox or Chrome, that navigates html pages by hypertext links, data browsers navigate linked data by RDF triples. Two examples of this are Tabulator and Marbles.
Another type of linked data application is linked data search engines and indexes, like Falcons. Similar to using a Google or Yahoo search engine, users can go here and search for linked data. For example, if we search for “Berlin,” we can narrow down the results by person, concept, place, etc. You cannot reach this level of granularity with a Google search. You can also create maps or diagrams with the triples the browser found.
While linked data browsers and search engines are useful tools, I believe that the most interesting possibilities rest in the other applications being developed. For example, many of the BBC’s webpages are automatically updated with information from Dbpedia, a linked data database that links Wikipedia pages. If we go to their programs or music webpage, you will see a great deal of content that is constantly being updated, added to, and changed by linked data applications.
 I’ve talked about what the linked data problem is, the technological foundation used to link data, and some of the uses for this data. I want to now turn my attention to why libraries are linking their data. The first reason is that linking your OPAC records and repository items will allow search engines, like Google or Yahoo, to index your records. Users would then see your records in their search results. It also opens up the possibility of more creative applications using library data. For example, a website could automatically feature your records in its display, the way that some of the BBC webpages do with Wikipedia information.
I’ve talked about what the linked data problem is, the technological foundation used to link data, and some of the uses for this data. I want to now turn my attention to why libraries are linking their data. The first reason is that linking your OPAC records and repository items will allow search engines, like Google or Yahoo, to index your records. Users would then see your records in their search results. It also opens up the possibility of more creative applications using library data. For example, a website could automatically feature your records in its display, the way that some of the BBC webpages do with Wikipedia information.
WorldCat already provides RDF triples with its records. If we go to this WorldCat record for the book Cat and scroll all the way to the bottom, there is an option to display the RDF record.
 So how are libraries linking their data? Some are using the RDF encoding standard in their institutional repositories and digital libraries. Some are linking their OPAC records through Bibframe. Bibframe is an encoding standard used to link library OPAC records. Fields are parsed out more granularly with emphasis on relationships for better machine-readability. It is believed that this encoding standard will allow search engines and other applications to index and use these records.
So how are libraries linking their data? Some are using the RDF encoding standard in their institutional repositories and digital libraries. Some are linking their OPAC records through Bibframe. Bibframe is an encoding standard used to link library OPAC records. Fields are parsed out more granularly with emphasis on relationships for better machine-readability. It is believed that this encoding standard will allow search engines and other applications to index and use these records.
 Here is an example of a Bibframe book record. You will notice that is it much longer than the original MARC record. The relationships between the fields and the origin of the information are better explained.
Here is an example of a Bibframe book record. You will notice that is it much longer than the original MARC record. The relationships between the fields and the origin of the information are better explained.
 I have argued that all new catalogers need to understand the importance of linked data and why and how libraries are starting linked data initiatives. I would like to conclude this post with when libraries should start linked data initiatives.
I have argued that all new catalogers need to understand the importance of linked data and why and how libraries are starting linked data initiatives. I would like to conclude this post with when libraries should start linked data initiatives.
There are a lot of unresolved issues in the current linked data climate. Practices have not been firmly established, especially controlled vocabulary. Digital library and ILS systems do not automatically support linked data. And of course, any new initiative takes time and money.
Libraries need to evaluate the needs of their patrons. Is your library serving a community that would benefit from linked data initiatives? What staff skills could your library pull from? And does your library have unique items that need better discovery and access points from outside search engines?
Is linked data something your library is ready to explore?